张量编程的第一性原理#
引言#
这个学期基于 FEALPy 给研究生和本科生上偏微分方程数值解的程序设计课,又讲到了数组编程(Array Programming),有了一些新的认识,就总结记录下来,以期可以引起更多思考和讨论。
数组编程也叫 向量(Vectorization)编程 。不管数组,还是向量,其实都是计算机的叫法。对于数学来说,我认为 张量编程(Tensor Programming) 的叫法更亲切合适一点,因为它暗示了这种编程技术有坚实的数学理论基础。
多维数组的概念是数学中一般张量概念的计算机实现,本质是一种数据结构,更强调如何把多维数组放到一维的内存结构中,多维数组运算背后的原理就是张量计算。
我不喜欢“向量编程”这个叫法。虽然向量也是数学中常用的概念,但向量编程中的向量,根本不是数学中的向量(有大小和方向的量)。它与 CPU 的单指令多数据(SIMD)并行机制有关,强调的是一条指令可以同时处理很多组数据。“向量编程”这种叫法,对于数学系的学生,会造成很多认知上的无谓障碍。
因此,下面尽量使用“张量编程”这个说法,也会用 张量(Tensor) 代替“多维数组”这个概念。但要强调一下,这里的张量并不是那种最抽象的张量概念,就纯粹指一个多维数表或数组,就像《高等代数》中说“矩阵就是一个二维数表”一样,而矩阵其实就是一类特殊的张量——二阶张量。
下面让我们尝试回答:
张量编程的第一性原理是什么?
注意,这里不是指张量计算的第一性原理。所谓“张量编程的第一性原理”,是可以指导张量编程实践的一般性原理,或者说是思维框架。
给定一个与实际问题相关的算法,这个一般性原理可以有效指导我们:
用张量来统一描述算法中涉及的数学对象,
高效组织算法涉及的输入、输出及中间数据,
并用张量运算来刻画整个算法流程。
下面,让我们借助 numpy 中的多维数组对象 ndarray(后文我们全部用“张量”代替“多维数组”)来尝试说清楚张量编程的第一性原理。
从多维张量到一维内存#
下面示例代码创建了一个二维张量 x,它除了有一个 data 属性指向一段连续的内存外,还附加了 dtype、shape(长度为 2 的元组)、strides(长度为 2 的元组)等属性,专门用来解释这一段内存的存储约定。
import numpy as np
x = np.arange(12).reshape(4, 3)
print(type(x))
print(x.dtype)
print(x.shape) # (4, 3)
print(x.strides) # (24, 8)
所谓 x 是二维的,只是一个逻辑概念,是相对于人而言,并不是指计算机内存物理上是二维的。
计算机内存本质上是一个一维的字节数组。因此这里就有一个基本的问题,就是如何把二维的 x 存储到一维的内存当中?有两种选择,按行或按列的方式,把二维张量展开放入 data 属性指向的一段连续内存中。
这里,我们选择按行展开的方式。当然不同的展开方式,会有不同的应用场景,后面再写文章细说。
示例中的二维张量 x,存储的数据类型为 64 位的整数,因此每个数据元素占 8 个字节。x 的形状为(4, 3) ,共存储了 12 个整数,占用内存长度为 96 个字节。
x 有两个轴,轴编号从 0 开始,第 0 轴长度为 4, 第 1 轴长度 3。为了方便从一维内存中存取数据,就必须知道每个轴的索引增加 1 时,实际的内存地址要增加多个少字节。 x.strides==(24, 8) 的解释如下:
第 0 轴的索引增加 1,内存地址要跨过一行 3 个整数占用的内存,共 3*8=24 个字节。
第 1 轴的索引增加 1,内存地址要跨过 1 个整数占用的内存,共 8 个字节。
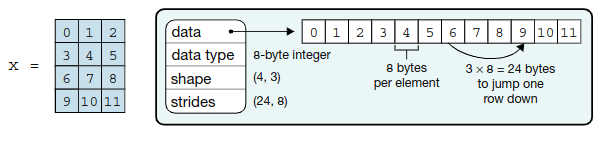
图1: 二维张量 x 的数据结构(内存结构)示意图
练一练 从
x用切片索引创建两个张量,创建方式分别为:
y = x[:, 1:]
z = x[:, ::2]请解释y和z的strides属性的取值意义。(提示:切片索引创建的x的视图,即还使用原来x的内存)
张量(多维数组)这个数据结构,要解决的主要矛盾,是数据逻辑上的多维和内存物理上的一维之间的矛盾。
一维内存的结构是线性的,而我们这个物理世界是多维非线性的,因此表示这个世界的很多数据也是多维非线性的。所以要想用计算机表示、模拟和预测这个世界, 就必须研究如何把多维非线性数据高效存储到线性内存中,这是数据结构研究要解决的关键问题。
对于想熟练掌握张量编程技术的人来说,深入理解这种从多维张量到一维内存的映射方式,是掌握张量编程中很多技巧、以及认识不同实现效率差异的关键基础。
但仅理解了多维张量到一维内存的映射,只是做好了张量编程的后一半工作。
从实际数学对象到多维张量表示#
张量编程的最终目的,是解决实际问题的模拟计算。因此,我们还需要解决如何把实际数学对象映射为多维张量的问题。
无论是什么应用场景,如果想用张量来表示实际数学对象,都必须问三个最基本的问题:
张量应该选取什么样的形状?
张量每个轴代表的实际意义是什么?
张量每个元素代表的实际意义是什么? 我的经验是,只要在大多数情况下,可以顺利回答这三个问题,就能说明一个人真正掌握了张量编程的精髓。
举个简单一点的例子,给定 NC 个二维三角形,用张量 x 来表示这组三角形,对应三个基本问题的答案为:
x的形状可以是(NC, 3, 2)。第 0 轴是三角形编号轴,第 1 轴是三角形顶点编号轴,第 2 轴为顶点坐标分量编号轴。
x[i, j, k]存储的是第i个三角形的第j个顶点的第k个分量的坐标值。
再举一个复杂一点的例子,给定 GD 维欧氏空间中的一个网格,包含 NC 个同类型的网格单元,每个网格单元上有 LDOF 个标量局部基函数(不防设为 Lagrange 基函数),要计算它们在 NQ 个积分点上的梯度值,用一个张量 y 来存储这些梯度值,对应三个基本问题的答案为:
y的形状可以为(NC, LDOF, NQ, GD)。y的第 0 轴是网格单元编号轴,第 1 轴是单元局部基函数编号轴, 第 2 轴是单元积分点编号轴,第 3 轴为梯度分量编号轴。y[i, j, k, l]存储的是第i个网格单元上第j个基函数在k个积分点上的第l个梯度分量值。
练一练 在
GD维的欧氏空间中,有一个非结构三角形网格,含有NN个网格节点,NC个网格单元
请用
node和cell两个二维张量来表示这个三角形网格,并用上面的三个问题来解释。请解释
node[cell, :]索引操作的意义。
在上述四阶张量的基础上,再加上积分权重 w (一阶张量,形状为(NQ, )) 和网格单元测度 m (一阶张量,形状为 (NC, ) ),就可以利用 NumPy 的 einsum 函数来计算单元刚度矩阵 M
M = np.einsum('q, ciqd, cjqd, c->cij', w, y, y, m)
其中,
字符串
q, ciqd, cjqd, c->cij指定了张量计算的方式M对应的指标符号为cij,w对应的指标符号为q,第一个参数y对应的指标符号为ciqd, 第二个y对应的指标为cjqd,m对应的指标为c。一个字母代表一个指标轴
注意,传统的爱因斯坦求和约定,有哑标(重复出现的指标)和自由标(只出现一次的指标)的概念。但 np.einsum 指定哑标和自由标的方式不一样,如果计算结果张量的下标出现在计算结果张量的下标中,则称其为自由标,反之称其为哑标(要对其求和)。上面例子中,积分点下标 q 和梯度分量下标 d 都没有出现在 cij 中,所以是哑标,因此要求和,分别对应了积分求和和向量内积运算。
如何理解张量 M 呢?还是给出三个基本问题的答案:
M的形状为(NC, LDOF, LDOF)。M的第 0 轴为网格单元编号轴,第 1 轴为网格单元局部基函数编号轴,第 2 轴也为网格单元局部基函数编号轴。M[c, i, j]代表第c个单元上的第i个基函数 \(\phi_i\) 与第j个基函数 \(\phi_j\) 的梯度内积,即 \(\int_{\tau_c}\nabla\phi_i\cdot\nabla\phi_j\,\mathrm{d}\boldsymbol{x}\)。
总结#
本文尝试讨论了可以指导张量编程的第一性原理,或者说是思维框架。我现在给研究生和本科生上编程课,就是用这三个问题来讲,感觉效果不错。
注意上面的思维框架,只是基本解决了如何把一般的数学对象或算法转化为程序的问题。
但在解决实际问题当中,还有如何把实际问题翻译成数学问题的过程,这个更难,因为这要求一个人,不但要懂数学,还要能理解自然、科学与工程中的语言。
虽然难,但我认为相对于其他学科背景的人,数学人更有可能承担其这个翻译者的角色(因为数学是一切科学的通行语言),前提是能够克服内心的成见,像历史上那些伟大的数学先辈一样, 真正勇敢走到一线去。